Reinforcement Learning with Metacognitive Feedback Elicits Faithful Uncertainty Expression in LLMs
Abstract
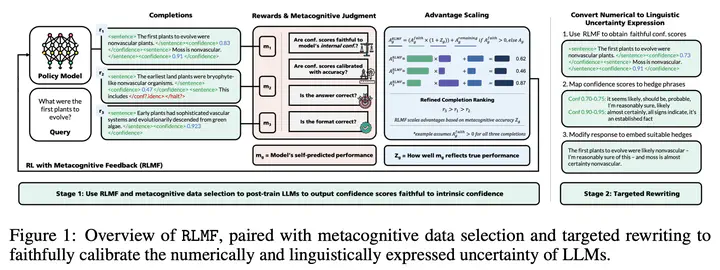
Metacognition is a critical component of intelligence which describes the ability to monitor and regulate one’s own cognitive processes. Yet LLMs exhibit systemic deficiencies in key metacognitive faculties: they hallucinate with high confidence, fail to recognize knowledge boundaries, and misrepresent their internal uncertainty-undermining trustworthiness and reliability. Since monitoring task performance and adapting behavior accordingly are central to metacognition, we posit that models capable of accurately judging their own performance are better positioned to improve it. We operationalize this idea via two novel mechanisms: reinforcement learning with metacognitive feedback (RLMF), a paradigm to refine completion rankings during preference optimization based on the quality of a model’s self-judgments of performance, and metacognitive data selection, which leverages similar self-judgments to identify high-value training examples, outperforming naive active learning. We apply these innovations to the problem of faithful calibration (FC), a task that is itself fundamentally metacognitive: the goal is to align expressed with intrinsic uncertainty, challenging even for frontier LLMs. We adopt a two-stage, decoupled approach, first using these methods to calibrate the faithfulness of models’ self-reported confidence scores, then mapping to natural, context-adaptable linguistic uncertainty via targeted output editing. Extensive experiments show our framework achieves generalizable, state-of-the-art FC across a wide array of datasets, while preserving task accuracy. Importantly, RLMF surpasses standard RL to strengthen post-training outcomes by up to 63% while enhancing models’ ability to recognize and communicate their own capability limits. This positions RLMF as a promising paradigm for encoding metacognitive awareness into LLMs toward improved abilities and alignment, and suggests metacognitive performance as an effective RL signal that can overcome limitations of prior intrinsic feedback methods.