Gabrielle Kaili-May Liu
Gabrielle Kaili-May Liu
Home
Publications
Teaching
CV
Light
Dark
Automatic
Publications
Type
Conference paper
Journal article
Preprint
Date
2026
2025
2024
2023
2022
2021
2019
2018
Metacognition in LLMs: Foundations, Progress, and Opportunities
Metacognition is a foundational component of intelligence that has become increasingly recognized as a cornerstone of capable, transparent AI systems. While LLMs have made significant progress, it remains unclear when, how, or to what extent they can exhibit or be endowed with effective metacognitive abilities, and how such abilities can be adapted to advance the fundamental capabilities, reliability, and intelligence of AI systems. This paper bridges this gap by presenting the first systematic, comprehensive review of the current state of knowledge on metacognition for LLMs. See the GitHub repo for the full paper list!
Gabrielle Kaili-May Liu
,
Areeb Gani
,
Jacqueline Lu
,
Jordan Thomas
,
Mark Steyvers
,
Arman Cohan
2026
PDF
Cite
GitHub (Paper List)
Reinforcement Learning with Metacognitive Feedback Elicits Faithful Uncertainty Expression in LLMs
Metacognition is core to intelligence and describes the ability to monitor and regulate one’s own cognition. Yet LLMs exhibit systemic deficiencies in key metacognitive faculties. Since monitoring task performance and adapting behavior accordingly are central to metacognition, we posit that models capable of accurately judging their own performance are better positioned to improve it, making metacognitive signals a natural source of supervision during post-training. We introduce reinforcement learning with metacognitive feedback (RLMF), a training paradigm to reward models for exhibiting good performance 𝗮𝗻𝗱 good metacognition. We also propose metacognitive data selection: using a model’s self-assessments to choose informative training samples. We showcase the value of RLMF & MDS by applying them to tackle faithful calibration, challenging even for frontier LLMs, achieving SOTA results while improving metacognitive monitoring in LLMs.
Gabrielle Kaili-May Liu
,
Avi Caciularu
,
Gal Yona
,
Idan Szpektor
,
Arman Cohan
2026
COLM
PDF
Cite
Code
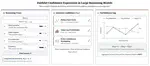
Quantifying Faithful Confidence Expression in Large Reasoning Models
We introduce a novel framework to systematically quantify faithful calibration—the alignment between expressed and intrinsic confidence—of large reasoning models (LRMs) in long-form reasoning settings. We analyze linguistic decisiveness relative to three sources of internal uncertainty, based on token probabilities, hidden states, and sampled response consistency. We also devise a prefix-conditioned sampling approach to control for conditional and structural variation across traces.
Gabrielle Kaili-May Liu
,
Areeb Gani
,
Asal Meskin
,
Arman Cohan
2026
ICML Trustworthy AI4GOOD Workshop (Spotlight 🌟); Submission to NeurIPS
PDF
Cite
Code
Investigating Retrieval-Augmented Generation Systems on Unanswerable, Uncheatable, Realistic, Multi-hop Queries
We present the first pipeline for automatic, difficulty-controlled creation of uncheatable, realistic, unanswerable, and multi-hop queries (CRUMQs), adaptable to any corpus and domain. This offers a simple way to enhance benchmark difficulty and realism and drive development of more capable RAG systems.
Gabrielle Kaili-May Liu
,
Bryan Li
,
Arman Cohan
,
William Gantt Walden
,
Eugene Yang
2026
ECIR
PDF
Cite
Code
Incorporating Q&A Nuggets into Retrieval-Augmented Generation
Nugget-based evaluation methods have emerged as the standard for measuring relevance of long-form RAG responses. We argue that nuggets are valuable also for guiding retrieval and generation, and we present a nugget-centric RAG system that automatically constructs its own nugget bank and uses it as a control signal throughout the pipeline.
Laura Dietz
,
Bryan Li
,
Gabrielle Kaili-May Liu
,
Jia-Huei Ju
,
Eugene Yang
,
Dawn Lawrie
,
William Gantt Walden
,
James Mayfield
2026
ECIR
PDF
Cite
Code
DoGMaTiQ: Automated Generation of Question-and-Answer Nuggets for Report Evaluation
Evaluation of long-form, citation-backed reports typically depends on use of atomic, QA-based nuggets to assess coverage of query-relevant information. This largely depends on manual curation of sets of nuggets per test topic. To improve scalability, we introduce DoGMaTiQ, a pipeline to generate high-quality QA nugget sets, and integrate it with Auto-ARGUE, a recent nugget-based evaluation framework, to enable fully automatic evaluation of generated reports.
Bryan Li
,
William Gantt Walden
,
Yu Hou
,
Gabrielle Kaili-May Liu
,
Dawn Lawrie
,
James Mayfield
,
Eugene Yang
,
Chris Callison-Burch
,
Laura Dietz
2026
SIGIR ICTIR
PDF
Cite
Code
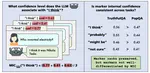
Can LLMs Use Linguistic Uncertainty Markers to Reliably Reflect Intrinsic Confidence?
The first systematic study of whether epistemic markers emitted by LLMs consistently and stably reflect their intrinsic confidence. We operationalize
marker internal confidence
(MIC) as the internal confidence level an LLM associates with a specific epistemic marker, and introduce a suite of 7 metrics to evaluate the in- and out-of-distribution reliability of MICs across diverse models and tasks.
Gabrielle Kaili-May Liu
,
Arman Cohan
2026
Submission to EMNLP
PDF
Cite
Code
Auto-ARGUE: LLM-Based Report Generation Evaluation
Report generation (RG) is a RAG task that aims to produce a long-form, citation-attributed response to a complex user query. We present the first public, automated, LLM-based implementation of the ARGUE evaluation framework for RG.
William Gantt Walden
,
Marc Mason
,
Orion Weller
,
Laura Dietz
,
John Conroy
,
Neil Molino
,
Hannah Recknor
,
Bryan Li
,
Gabrielle Kaili-May Liu
,
Yu Hou
,
Dawn Lawrie
,
James Mayfield
,
Eugene Yang
2026
SIGIR
PDF
Cite
Code
Measuring what Matters: Construct Validity in Large Language Model Benchmarks
LLM benchmarks are essential for tracking progress and ensuring safety in AI, but most benchmarks don’t measure what matters, as suggested by our systematic review of 445 LLM benchmarks from top AI conferences. A taxonomy of these failures was therefore built and translated into an operational checklist to help future benchmark authors demonstrate construct validity.
Andrew M. Bean
,
Ryan Othniel Kearns
,
Angelika Romanou
,
Franziska Sofia Hafner
,
Harry Mayne
,
Others
,
Gabrielle Kaili-May Liu
,
Adam Mahdi
2025
NeurIPS
PDF
Cite
Code
Project
HF Repo
Checklist
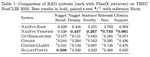
MetaFaith: Faithful Natural Language Uncertainty Expression in LLMs
For LLMs to be deployed reliably and responsibly, it is essential that their linguistically expressed confidence faithfully reflect their internal uncertainty. This paper presents the first study to systematically and comprehensively benchmark faithful calibration of LLMs and proposes MetaFaith, the first method to improve faithful calibration of any instruction-following LLM in a task-agnostic manner.
Gabrielle Kaili-May Liu
,
Gal Yona
,
Avi Caciularu
,
Idan Szpektor
,
Tim G. J. Rudner
,
Arman Cohan
2025
EMNLP Main
PDF
Cite
Code
Poster
Slides
MDCure: A Scalable Pipeline for Multi-Document Instruction-Following
Multi-document (MD) processing is crucial for LLMs to handle real-world tasks across large sets of documents. This paper introduces MDCure, an effective and scalable procedure for generating high-quality multi-document instruction tuning data to improve MD capabilities of any base LLM.
Gabrielle Kaili-May Liu
,
Bowen Shi
,
Avi Caciularu
,
Idan Szpektor
,
Arman Cohan
2025
ACL Main
PDF
Cite
Code
Poster
Slides
HF Repo
Exploring Quantitative Measures in Metacognition of Emotion
Metacognition of emotion refers to the ability to evaluate success at identifying one’s own emotional feelings and adjusting them accordingly. This paper establishes the first experimentally-validated procedure to reliably assess and quantify metacognition of emotion.
Hsing-Hao Lee
,
Gabrielle Kaili-May Liu
,
Yi-Chuan Chen
,
Su-Ling Yeh
2024
Scientific Reports
PDF
Cite
Perspectives on the Social Impacts of Reinforcement Learning with Human Feedback
This paper discusses the social implications of reinforcement learning with human feedback (RLHF), identifying key social and ethical issues and discussing social impacts for stakeholders. Seven impact areas are examined, including misinformation, AI value-alignment, bias, AI access, cross-cultural dialogue, industry, and workforce.
Gabrielle Kaili-May Liu
2023
Envisioning the Future of Computing Prize, MIT Schwarzman College of Computing
PDF
Cite
Slides
A Robot Rights Curriculum Informed by Western and Eastern Principles
An undergraduate-level curriculum that cultivates understanding of the robot rights debate as informed by Western and Eastern principles, stepping toward filling existing gaps in knowledge and discourse and uniting the global community. Constructs and works through a foundational framework to engage students in critical thinking, understanding, and discussion of decisions regarding robot rights.
Gabrielle Kaili-May Liu
2023
MIT Social and Ethical Responsibilities of Computing Symposium
Cite
Poster
Access Curriculum
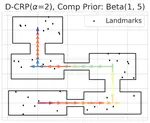
Streaming Inference for Infinite Non-Stationary Clustering
We define the Dynamical Chinese Restaurant Process (Dynamical CRP), a novel stochastic process that provides a non-stationary prior over cluster assignments and yields an efficient streaming variational inference algorithm. Experiments show the Dynamical CRP can be applied on diverse synthetic and real data with Gaussian and non-Gaussian likelihoods.
Rylan Schaeffer
,
Gabrielle Kaili-May Liu
,
Yilun Du
,
Scott Linderman
,
Ila Rani Fiete
2022
ICLR Workshop on Agent Learning in Open-Endedness & Conference on Lifelong Learning Agents
PDF
Cite
Poster
Streaming Inference for Infinite Feature Models
R-IBP is a novel recursive form of the Indian Buffet Process that makes feature models applicable to streaming data. It enables creation of new features online and in a probabilistic, principled manner. As a prior for feature models, R-IBP yields efficient inference over an unbounded number of latent features, with quasilinear average time complexity and logarithmic average space complexity.
Rylan Schaeffer
,
Yilun Du
,
Gabrielle Kaili-May Liu
,
Ila Rani Fiete
2022
ICML
PDF
Cite
Poster
I know I’m happy, and I’m right: Metacognition of emotion
The first experimentally quantitative index of metacognition of emotion. Advancing understanding of awareness toward subjective feelings.
Hsing-Hao Lee
,
Gabrielle Kaili-May Liu
,
Su-Ling Yeh
2021
European Conference on Visual Perception
PDF
Cite
Poster
Weight Friction: A Simple Method to Overcome Catastrophic Forgetting and Enable Continual Learning
Weight friction draws from principles in neuroscience and physics to help mitigate catatstrophic forgetting in neural networks. It operates over multiple task domains and has convergence comparable to SGD.
Gabrielle Kaili-May Liu
2019
Preprint
PDF
Cite
Evaluating Gammatone Frequency Cepstral Coefficients with Neural Networks for Emotion Recognition from Speech
GFCCs can be powerful speech features for use in speech emotion recognition. This preliminary study suggests they are more suitable versus MFCCs for emotion and intensity classification tasks with neural networks.
Gabrielle Kaili-May Liu
2018
Preprint
PDF
Cite
Cite
×